

GPT-based few-shot classification with the OpenAI API#
In the zero-shot classification tutorial you learned how to build a classifier that can perform reasonably well on a task that it has not been explicitly trained on. However, in other scenarios where the classification task can be more difficult, additional steps are required.
In this tutorial you will learn about few-shot learning, a convenient way to improve the model’s performance by showing it relevant examples without re-training or fine-tuning it. You will also dive deeper into understanding prompt tokens and get a glimpse of how LLMs can be evaluated.
Prerequisites#
Dataiku >= 11.4
“Use” permission on a code environment using Python >= 3.9 with the following packages:
openai(tested with version 0.27.7)tiktoken(tested with version 0.4.0)scikit-learn(tested with version 1.2.2)retry(tested with version 0.9.2)
Access to an existing project with the following permissions:
“Read project content”
“Write project content”
A valid OpenAI secret key
Reading and implementing the tutorial on zero-shot classification
Preparing the data#
For this tutorial you will work on a different dataset in order to predict more than two classes. This dataset is part
of the Amazon Review Dataset, and contains an extract of the “Magazine
subscriptions” category. Download the data file
here
and create a dataset called reviews_magazines with it in your project.
Counting tokens#
Language models process text in the form of tokens, which are recurring sequences of characters, to understand the statistical links between them and infer the next probable ones. Counting tokens in a text input is useful because:
It is the main pricing unit for managed LLM services (more details on OpenAI’s dedicated page),
It can be used to specify minimu/maximum thresholds on input and output lengths.
To enrich your dataset with the number of tokens per review, go to your project library and create a new directory
called gpt_utils. In that directory, add a empty __init__.py file as well as a tokens.py file with the following
content:
import tiktoken
def count_tokens(model: str, text: str) -> int:
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
Binning ratings and splitting the data#
Next, create a Python recipe with two outputs called reviews_mag_train and reviews_mag_test with the following
code:
import dataiku
import random
from gpt_utils.tokens import count_tokens
def bin_score(x):
return 'pos' if float(x) >= 4.0 else ('ntr' if float(x) == 3.0 else 'neg')
model = "gpt-3.5-turbo"
random.seed(1337)
input_dataset = dataiku.Dataset("reviews_magazines")
output_schema = [
{"type": "string", "name": "reviewText"},
{"type": "int", "name": "nb_tokens"},
{"type": "string", "name": "sentiment"}
]
train_dataset = dataiku.Dataset("reviews_mag_train")
train_dataset.write_schema(output_schema)
w_train = train_dataset.get_writer()
test_dataset = dataiku.Dataset("reviews_mag_test")
test_dataset.write_schema(output_schema)
w_test = test_dataset.get_writer()
for r in input_dataset.iter_rows():
text = r.get("reviewText")
if len(text) > 0:
out_row = {
"reviewText": text,
"nb_tokens": count_tokens(model, text),
"sentiment": bin_score(r.get("overall"))
}
rnd = random.random()
if rnd < 0.5:
w_train.write_row_dict(out_row)
else:
w_test.write_row_dict(out_row)
w_train.close()
w_test.close()
This code bins the rating scores from the overall column into a
new categorical column called sentiment where the values can be either:
pos(positive) for ratings \(\geq 4\),ntr(neutral) for ratings \(=3\),neg(negative) otherwise.
It also removes useless columns to keep only sentiment and reviewText (the content of the user review) and randomly
dispatches output rows between:
reviews_mag_teston which you’ll run and evaluate your classifier,reviews_mag_trainwhich role will be explained later.
Building a zero-shot-based baseline#
Begin by establishing a baseline using a zero-shot classification prompt on the test dataset.
Defining the prompt#
In your project library, under gpt_utils, create two files:
auth.pyto authenticate on the OpenAI API, see here for more detailsauth.py#import dataiku def get_api_key(secret_name: str) -> str: client = dataiku.api_client() auth_info = client.get_auth_info(with_secrets=True) secret_value = None for secret in auth_info["secrets"]: if secret["key"] == secret_name: secret_value = secret["value"] break if not secret_value: raise Exception("Secret not found") else: return secret_value
chat.pywith the following code:chat.py#import openai import json import requests from typing import List, Dict from retry.api import retry_call from openai.error import RateLimitError from openai.error import APIError from openai.error import TryAgain from openai.error import Timeout from openai.error import APIConnectionError from openai.error import ServiceUnavailableError from openai.error import InvalidRequestError from .auth import get_api_key DEFAULT_API_MAX_RETRIES = 3 DEFAULT_API_DELAY_TIME = 5 API_RETRY_EXCEPTIONS = ( requests.HTTPError, RateLimitError, APIError, TryAgain, Timeout, APIConnectionError, ServiceUnavailableError) API_CATCH_EXCEPTIONS = ( requests.HTTPError, RateLimitError, APIError, TryAgain, Timeout, APIConnectionError, ServiceUnavailableError, InvalidRequestError) def send_prompt_with_context(model: str, messages: List[Dict], temperature: int = 0, max_tokens: int = 500) -> Dict[str, str]: # Fetch API key stored in a Dataiku user secret called OPEN_AI_API_KEY openai.api_key = get_api_key("OPENAI_API_KEY") resp = openai.ChatCompletion.create( messages=messages, model=model, temperature=temperature, max_tokens=max_tokens ) return resp.choices[0].message["content"] def predict_sentiment(model: str, review: str): def predict_sentiment_without_retry() -> Dict[str, str]: system_msg = """ You are an assistant that classifies reviews according to their sentiment. \ Respond strictly with this JSON format: {"gpt_sentiment": "xxx"} where xxx should only be either: \ pos if the review is positive \ ntr if the review is neutral or does not contain enough information \ neg if the review is negative \ No other value is allowed. """ messages = [ {"role": "system", "content": system_msg}, {"role": "user", "content": f"Review: {review}"} ] answer = send_prompt_with_context(model, messages) return json.loads(answer) return retry_call(predict_sentiment_without_retry, exceptions=API_RETRY_EXCEPTIONS, delay=DEFAULT_API_DELAY_TIME, tries=DEFAULT_API_MAX_RETRIES)
Let’s unpack the content of chat.py:
send_prompt_with_context()wraps the call to the OpenAI API to easily enter the input text and retrieve the response.predict_sentiment()defines the multi-class classification task by telling the model which classes to expect (pos,ntr,neg) and how to format the output. It also relies on theretryPython package to handle transient failures while calling the OpenAI API (rate limitations, timeouts, etc.) by implementing a retry mechanism.
From there you can write the code for the zero-shot run.
Running and evaluating the model#
Create and run a Python recipe using reviews_mag_test as
input and a new dataset called test_zs_scored as output, then add the following code:
import dataiku
from gpt_utils.chat import predict_sentiment
model = "gpt-3.5-turbo"
input_dataset = dataiku.Dataset("reviews_mag_test")
new_cols = [
{"type": "string", "name": "gpt_sentiment"},
{"type": "int", "name": "nb_tokens"}
]
output_schema = input_dataset.read_schema() + new_cols
output_dataset = dataiku.Dataset("test_zs_scored")
output_dataset.write_schema(output_schema)
# Run prompts on test dataset
with output_dataset.get_writer() as w:
for i, r in enumerate(input_dataset.iter_rows()):
print(f"{i+1}")
out_row = {}
# Keep columns from input dataset
out_row.update(dict(r))
# Add GPT output
out_row.update(predict_sentiment(model=model,
review=r.get("reviewText")))
w.write_row_dict(out_row)
That recipe simply iterates over the test dataset and infers the review text’s sentiment in the gpt_sentiment column.
Once the test_zs_scored dataset is built, you can evaluate your classifier’s performance: in your project library
create a new file under gpt_utils called evaluate.py with the following code:
import pandas as pd
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from typing import Dict
def get_classif_metrics(df: pd.DataFrame,
pred_col: str,
truth_col: str) -> Dict[str, float]:
metrics = {
"precision": precision_score(y_pred=df[pred_col],
y_true=df[truth_col],
average="macro"),
"recall": recall_score(y_pred=df[pred_col],
y_true=df[truth_col],
average="macro")
}
return metrics
You can now use the get_classif_metrics() function to compute the accuracy and f1 scores on the test dataset by runnning
the following code in a notebook:
import dataiku
from gpt_utils.evaluate import get_classif_metrics
df = dataiku.Dataset("test_zs_scored") \
.get_dataframe(columns=["sentiment", "gpt_sentiment"])
metrics_zs = get_classif_metrics(df, "gpt_sentiment", "sentiment")
print(metrics_zs)
{'accuracy': 0.82, 'f1': 0.67}
Implementing few-shot learning#
Next, you’ll attempt to improve the baseline model’s performance using few-shot learning, which supplements the model with training examples via the prompt, avoiding any retraining.
There are many ways to identify relevant training examples, in this tutorial you will use a rather intuitive approach:
start by running a zero-shot classification on the training dataset,
flag a subset of the resulting false positives/negatives to add to your prompt at evaluation time.
Retrieving relevant examples#
Create and run a Python recipe using reviews_mag_train as input and a new dataset called train_fs_examples as output
with the following code:
import dataiku
from gpt_utils.chat import predict_sentiment
SIZE_EX_MIN = 20
SIZE_EX_MAX = 100
NB_EX_MAX = 10
model = "gpt-3.5-turbo"
input_dataset = dataiku.Dataset("reviews_mag_train")
input_schema = input_dataset.read_schema()
output_dataset = dataiku.Dataset("train_fs_examples")
new_cols = [
{"type": "string", "name": "gpt_sentiment"}
]
output_schema = input_schema + new_cols
output_dataset.write_schema(output_schema)
nb_ex = 0
with output_dataset.get_writer() as w:
for r in input_dataset.iter_rows():
# Check token-base length
nb_tokens = r.get("nb_tokens")
if nb_tokens > SIZE_EX_MIN and nb_tokens < SIZE_EX_MAX:
pred = predict_sentiment(model=model,
review=r.get("reviewText"))
# Keep prediction only if it was mistaken
if pred["gpt_sentiment"] != r.get("sentiment"):
out_row = dict(r)
out_row["gpt_sentiment"] = pred["gpt_sentiment"]
w.write_row_dict(out_row)
nb_ex += 1
if nb_ex == NB_EX_MAX:
break
This code iterates over the training data, filters out the reviews which (token-based) size is not between SIZE_EX_MIN
and SIZE_EX_MAX then writes the prediction in the output dataset only if it was mistaken. There is also a limit of
10 examples defined by NB_EX_MAX to make sure that at evaluation time the augmented prompts do not increase the model’s
cost and execution time too much.
Running and evaluating the new model#
The next step is to incorporate those examples into your prompt before re-running the classification process.
Let’s start by updating the prompt: when using the OpenAI API, it consists in adding examples in the form of user/assistant
exchanges following the system message. To apply this, in your project library’s chat.py file add the following
functions:
def build_example_msg(rec: Dict) -> List[Dict]:
example = [
{"role": "user", "content": f"Review: {rec['reviewText']}"},
{"role": "assistant",
"content": json.dumps({"gpt_sentiment": rec['sentiment']})}
]
return example
The build_example_msg() function helps transforming a record’s raw data into dicts that follow the OpenAI API’s
message formalism.
def predict_sentiment_fs(model: str,
review: str,
examples: List[Dict]):
def predict_sentiment_fs_without_retry() -> Dict[str, str]:
system_msg = """
You are an assistant that classifies reviews according to their sentiment. \
Respond strictly with this JSON format: {"gpt_sentiment": "xxx"} where xxx should only be either: \
pos if the review is positive or thankful or optimistic \
ntr if the review is neutral or too short and does not contain enough information \
neg if the review is negative\
No other value is allowed.
"""
messages = [
{"role": "system", "content": system_msg}
]
messages += examples
messages.append(
{"role": "user", "content": f"Review: {review}"}
)
answer = send_prompt_with_context(model, messages)
return json.loads(answer)
return retry_call(predict_sentiment_fs_without_retry,
exceptions=API_RETRY_EXCEPTIONS,
delay=DEFAULT_API_DELAY_TIME,
tries=DEFAULT_API_MAX_RETRIES)
The predict_sentiment_fs() function is a modified version of predict_sentiment() that adds a new examples argument
to enrich the prompt for few-shot learning.
With these new tools, you can now execute a few-shot learning run on the test dataset! Create a Python recipe with
test_fs_examples and reviews_mag_test as input, and a new output dataset called test_fs_scored. Add the following
code before running it:
import dataiku
from gpt_utils.chat import predict_sentiment_fs
from gpt_utils.chat import build_example_msg
MIN_EX_LEN = 5
MAX_EX_LEN = 200
MAX_NB_EX = 20
model = "gpt-3.5-turbo"
# Retrieve a few examples from the training dataset
examples_dataset = dataiku.Dataset("train_fs_examples")
ex_to_add = []
tot_tokens = 0
for r in examples_dataset.iter_rows():
nb_tokens = r.get("nb_tokens")
if (nb_tokens > MIN_EX_LEN and nb_tokens < MAX_EX_LEN):
ex_to_add += build_example_msg(dict(r))
tot_tokens += nb_tokens
if len(ex_to_add) == MAX_NB_EX:
print(f"Total tokens = {tot_tokens}")
break
test_dataset = dataiku.Dataset("reviews_mag_test")
new_cols = [
{"type": "string", "name": "gpt_sentiment"},
{"type": "int", "name": "nb_tokens"}
]
output_schema = test_dataset.read_schema() + new_cols
output_dataset = dataiku.Dataset("test_fs_scored")
output_dataset.write_schema(output_schema)
# Run prompts enriched with examples on test dataset
with output_dataset.get_writer() as w:
for r in test_dataset.iter_rows():
out_row = {}
# Keep columns from input dataset
out_row.update(dict(r))
# Add GPT output
out_row.update(predict_sentiment_fs(model=model,
review=r.get("reviewText"),
examples=ex_to_add))
w.write_row_dict(out_row)
You can now finally assess the benefits of few-shot learning by comparing the classifier’s performance with and without the examples! To do so, run this code in a notebook:
import dataiku
from gpt_utils.evaluate import get_classif_metrics
metrics = {}
for xs in ("zs", "fs"):
df = dataiku.Dataset(f"test_{xs}_scored") \
.get_dataframe(columns=["sentiment", "gpt_sentiment"])
metrics[xs] = get_classif_metrics(df, "gpt_sentiment", "sentiment")
print(metrics)
{'zs': {'accuracy': 0.82, 'f1': 0.67}, 'fs': {'accuracy': 0.85, 'f1': 0.7}}
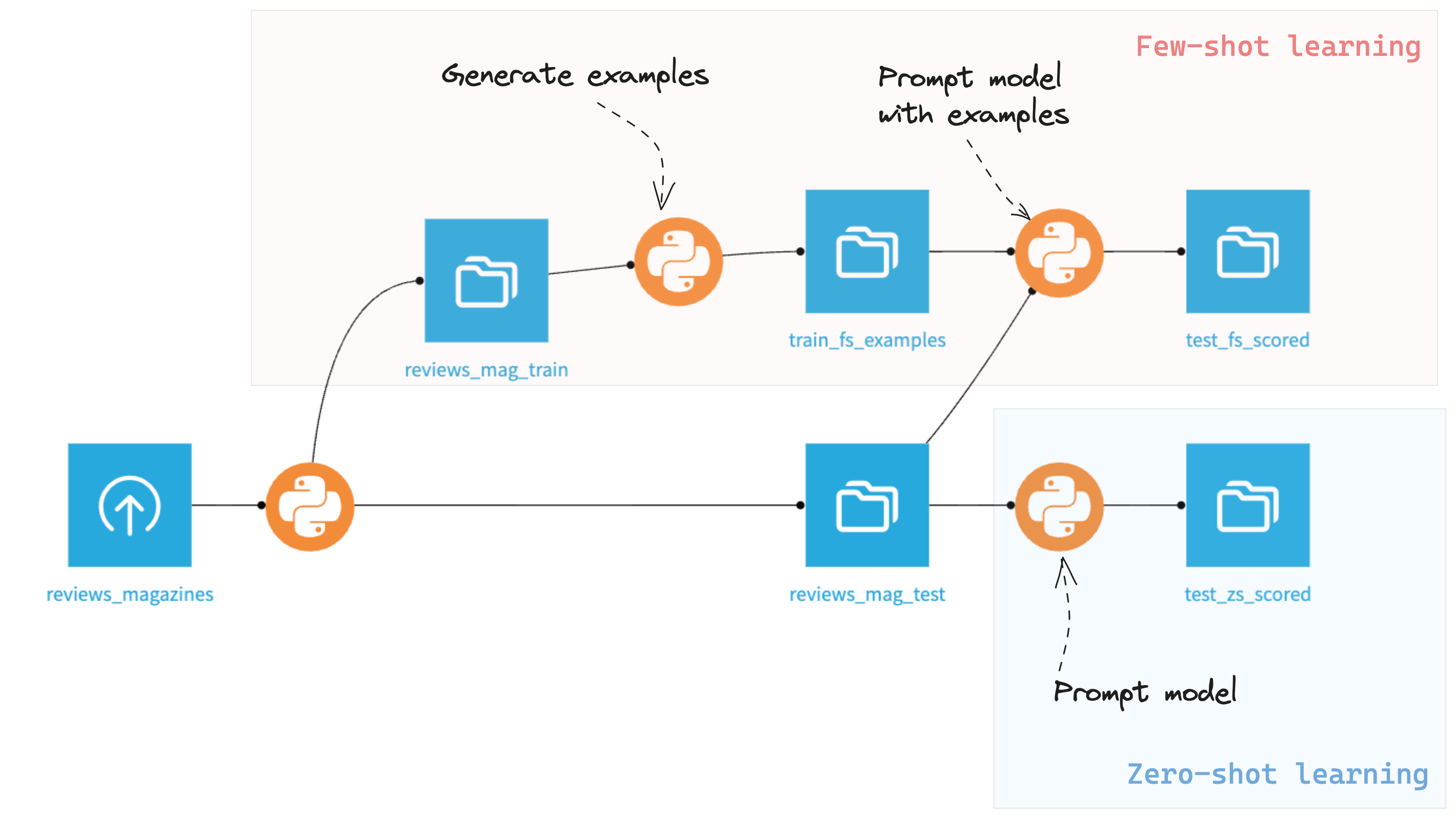
Your Flow has reached its final form and should look like this:
Wrapping up#
Congratulations for finish this (lengthy!) tutorial on few-shot learning! You know have a better overview of how to enrich a prompt to improve the behavior of a LLM such as GPT on a classification task. Feel free to play with the prompt and the various parameters to see how it can influence the model’s performance! You can also explore other leads to improve the tutorial’s code:
From a ML perspective, the datasets suffer from class imbalance since there are much more positive reviews than negative or neutral ones. You can mitigate that by resampling the initial dataset or by setting up class weights. You can also adjust the number and classes of the few-shot examples to help classifying data points belonging to the minority classes.
From a tooling perspective, you can make prompt building even more modular by relying on libraries such as Langchain or Guidance that offer rich prompt templating features.
If you’re looking for a high-level overview of how Dataiku can leverage LLMs for text classification, check out this blog post. Finally, you will find below the complete versions of the code presented in this tutorial.
Happy prompt engineering !
auth.py
import dataiku
def get_api_key(secret_name: str) -> str:
client = dataiku.api_client()
auth_info = client.get_auth_info(with_secrets=True)
secret_value = None
for secret in auth_info["secrets"]:
if secret["key"] == secret_name:
secret_value = secret["value"]
break
if not secret_value:
raise Exception("Secret not found")
else:
return secret_value
chat.py
import openai
import json
import requests
from typing import List, Dict
from retry.api import retry_call
from openai.error import RateLimitError
from openai.error import APIError
from openai.error import TryAgain
from openai.error import Timeout
from openai.error import APIConnectionError
from openai.error import ServiceUnavailableError
from openai.error import InvalidRequestError
from .auth import get_api_key
DEFAULT_API_MAX_RETRIES = 3
DEFAULT_API_DELAY_TIME = 5
API_RETRY_EXCEPTIONS = (
requests.HTTPError,
RateLimitError,
APIError,
TryAgain,
Timeout,
APIConnectionError,
ServiceUnavailableError)
API_CATCH_EXCEPTIONS = (
requests.HTTPError,
RateLimitError,
APIError,
TryAgain,
Timeout,
APIConnectionError,
ServiceUnavailableError,
InvalidRequestError)
def send_prompt_with_context(model: str,
messages: List[Dict],
temperature: int = 0,
max_tokens: int = 500) -> Dict[str, str]:
# Fetch API key stored in a Dataiku user secret called OPEN_AI_API_KEY
openai.api_key = get_api_key("OPENAI_API_KEY")
resp = openai.ChatCompletion.create(
messages=messages,
model=model,
temperature=temperature,
max_tokens=max_tokens
)
return resp.choices[0].message["content"]
def predict_sentiment(model: str, review: str):
def predict_sentiment_without_retry() -> Dict[str, str]:
system_msg = """
You are an assistant that classifies reviews according to their sentiment. \
Respond strictly with this JSON format: {"gpt_sentiment": "xxx"} where xxx should only be either: \
pos if the review is positive \
ntr if the review is neutral or does not contain enough information \
neg if the review is negative \
No other value is allowed.
"""
messages = [
{"role": "system", "content": system_msg},
{"role": "user", "content": f"Review: {review}"}
]
answer = send_prompt_with_context(model, messages)
return json.loads(answer)
return retry_call(predict_sentiment_without_retry,
exceptions=API_RETRY_EXCEPTIONS,
delay=DEFAULT_API_DELAY_TIME,
tries=DEFAULT_API_MAX_RETRIES)
def build_example_msg(rec: Dict) -> List[Dict]:
example = [
{"role": "user", "content": f"Review: {rec['reviewText']}"},
{"role": "assistant",
"content": json.dumps({"gpt_sentiment": rec['sentiment']})}
]
return example
def predict_sentiment_fs(model: str,
review: str,
examples: List[Dict]):
def predict_sentiment_fs_without_retry() -> Dict[str, str]:
system_msg = """
You are an assistant that classifies reviews according to their sentiment. \
Respond strictly with this JSON format: {"gpt_sentiment": "xxx"} where xxx should only be either: \
pos if the review is positive or thankful or optimistic \
ntr if the review is neutral or too short and does not contain enough information \
neg if the review is negative\
No other value is allowed.
"""
messages = [
{"role": "system", "content": system_msg}
]
messages += examples
messages.append(
{"role": "user", "content": f"Review: {review}"}
)
answer = send_prompt_with_context(model, messages)
return json.loads(answer)
return retry_call(predict_sentiment_fs_without_retry,
exceptions=API_RETRY_EXCEPTIONS,
delay=DEFAULT_API_DELAY_TIME,
tries=DEFAULT_API_MAX_RETRIES)
compute_reviews_mag_train.py
import dataiku
import random
from gpt_utils.tokens import count_tokens
def bin_score(x):
return 'pos' if float(x) >= 4.0 else ('ntr' if float(x) == 3.0 else 'neg')
model = "gpt-3.5-turbo"
random.seed(1337)
input_dataset = dataiku.Dataset("reviews_magazines")
output_schema = [
{"type": "string", "name": "reviewText"},
{"type": "int", "name": "nb_tokens"},
{"type": "string", "name": "sentiment"}
]
train_dataset = dataiku.Dataset("reviews_mag_train")
train_dataset.write_schema(output_schema)
w_train = train_dataset.get_writer()
test_dataset = dataiku.Dataset("reviews_mag_test")
test_dataset.write_schema(output_schema)
w_test = test_dataset.get_writer()
for r in input_dataset.iter_rows():
text = r.get("reviewText")
if len(text) > 0:
out_row = {
"reviewText": text,
"nb_tokens": count_tokens(model, text),
"sentiment": bin_score(r.get("overall"))
}
rnd = random.random()
if rnd < 0.5:
w_train.write_row_dict(out_row)
else:
w_test.write_row_dict(out_row)
w_train.close()
w_test.close()
compute_test_fs_scored.py
import dataiku
from gpt_utils.chat import predict_sentiment_fs
from gpt_utils.chat import build_example_msg
MIN_EX_LEN = 5
MAX_EX_LEN = 200
MAX_NB_EX = 20
model = "gpt-3.5-turbo"
# Retrieve a few examples from the training dataset
examples_dataset = dataiku.Dataset("train_fs_examples")
ex_to_add = []
tot_tokens = 0
for r in examples_dataset.iter_rows():
nb_tokens = r.get("nb_tokens")
if (nb_tokens > MIN_EX_LEN and nb_tokens < MAX_EX_LEN):
ex_to_add += build_example_msg(dict(r))
tot_tokens += nb_tokens
if len(ex_to_add) == MAX_NB_EX:
print(f"Total tokens = {tot_tokens}")
break
test_dataset = dataiku.Dataset("reviews_mag_test")
new_cols = [
{"type": "string", "name": "gpt_sentiment"},
{"type": "int", "name": "nb_tokens"}
]
output_schema = test_dataset.read_schema() + new_cols
output_dataset = dataiku.Dataset("test_fs_scored")
output_dataset.write_schema(output_schema)
# Run prompts enriched with examples on test dataset
with output_dataset.get_writer() as w:
for r in test_dataset.iter_rows():
out_row = {}
# Keep columns from input dataset
out_row.update(dict(r))
# Add GPT output
out_row.update(predict_sentiment_fs(model=model,
review=r.get("reviewText"),
examples=ex_to_add))
w.write_row_dict(out_row)
compute_test_zs_scored.py
import dataiku
from gpt_utils.chat import predict_sentiment
model = "gpt-3.5-turbo"
input_dataset = dataiku.Dataset("reviews_mag_test")
new_cols = [
{"type": "string", "name": "gpt_sentiment"},
{"type": "int", "name": "nb_tokens"}
]
output_schema = input_dataset.read_schema() + new_cols
output_dataset = dataiku.Dataset("test_zs_scored")
output_dataset.write_schema(output_schema)
# Run prompts on test dataset
with output_dataset.get_writer() as w:
for i, r in enumerate(input_dataset.iter_rows()):
print(f"{i+1}")
out_row = {}
# Keep columns from input dataset
out_row.update(dict(r))
# Add GPT output
out_row.update(predict_sentiment(model=model,
review=r.get("reviewText")))
w.write_row_dict(out_row)
compute_train_fs_examples.py
import dataiku
from gpt_utils.chat import predict_sentiment
SIZE_EX_MIN = 20
SIZE_EX_MAX = 100
NB_EX_MAX = 10
model = "gpt-3.5-turbo"
input_dataset = dataiku.Dataset("reviews_mag_train")
input_schema = input_dataset.read_schema()
output_dataset = dataiku.Dataset("train_fs_examples")
new_cols = [
{"type": "string", "name": "gpt_sentiment"}
]
output_schema = input_schema + new_cols
output_dataset.write_schema(output_schema)
nb_ex = 0
with output_dataset.get_writer() as w:
for r in input_dataset.iter_rows():
# Check token-base length
nb_tokens = r.get("nb_tokens")
if nb_tokens > SIZE_EX_MIN and nb_tokens < SIZE_EX_MAX:
pred = predict_sentiment(model=model,
review=r.get("reviewText"))
# Keep prediction only if it was mistaken
if pred["gpt_sentiment"] != r.get("sentiment"):
out_row = dict(r)
out_row["gpt_sentiment"] = pred["gpt_sentiment"]
w.write_row_dict(out_row)
nb_ex += 1
if nb_ex == NB_EX_MAX:
break
evaluate.py
import pandas as pd
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from typing import Dict
def get_classif_metrics(df: pd.DataFrame,
pred_col: str,
truth_col: str) -> Dict[str, float]:
metrics = {
"precision": precision_score(y_pred=df[pred_col],
y_true=df[truth_col],
average="macro"),
"recall": recall_score(y_pred=df[pred_col],
y_true=df[truth_col],
average="macro")
}
return metrics
tokens.py
import tiktoken
def count_tokens(model: str, text: str) -> int:
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))