

Creating a plugin Dataset component#
Prerequisites#
Dataiku >= 12.0
Access to a dataiku instance with the “Develop plugins” permissions
- Access to an existing project with the following permissions:
“Read project content.”
“Write project content.”
Access to an existing plugin
It would be best to have:
A dedicated Dataiku instance with admin rights (you can rely on the community Dataiku instance).
Attention
We highly recommend a separate, dedicated instance for plugin development. That way, you can test and develop the plugin without affecting Dataiku projects or jeopardizing other users’ experience. Attentive readers should read this introduction first (Foreword).
Introduction#
Dataiku’s Plugin Dataset component provides users with a flexible approach to creating and integrating custom datasets into their data projects. It allows users to import and work with data from their specific sources, expanding the range of data and formats they can use in Dataiku. This enables users to integrate their unique data sources and leverage the full power of Dataiku for data preparation, analysis, and modeling.
The plugin Dataset component is particularly useful for working with specialized data sources, APIs, or data generation processes not supported natively in Dataiku. Users can write custom code to fetch data from APIs, databases, or other sources and apply any necessary transformations or preprocessing steps to suit their needs.
Creating custom datasets in Dataiku using the plugin Dataset component has several benefits:
Users have complete control over the data fetching and transformation process, allowing them to customize it according to their requirements.
Custom datasets can seamlessly integrate with other features in Dataiku, such as recipes, visualizations, and models. This allows users to leverage the custom datasets in data pipelines, workflows, and machine learning projects.
Custom datasets can be reused across multiple projects within Dataiku, saving time and effort by eliminating the need to recreate the same data fetching and transformation logic for each project.
Finally, the plugin Dataset component provides:
An extensible framework for adding new data sources or formats to Dataiku.
Allowing users to contribute or share their plugins with the Dataiku community.
Expanding the platform’s capabilities.
Overall, the plugin Dataset component empowers users to work with diverse and unique data sources, customize data processing workflows, and seamlessly integrate custom datasets into their data projects in Dataiku.
Dataset component creation#
To create a plugin Dataset component, go to the plugin editor, click the + New component button (Fig. 1), and choose the Dataset component (Fig. 2). If you do not already have a plugin created, you can follow this tutorial (Creating and configuring a plugin).
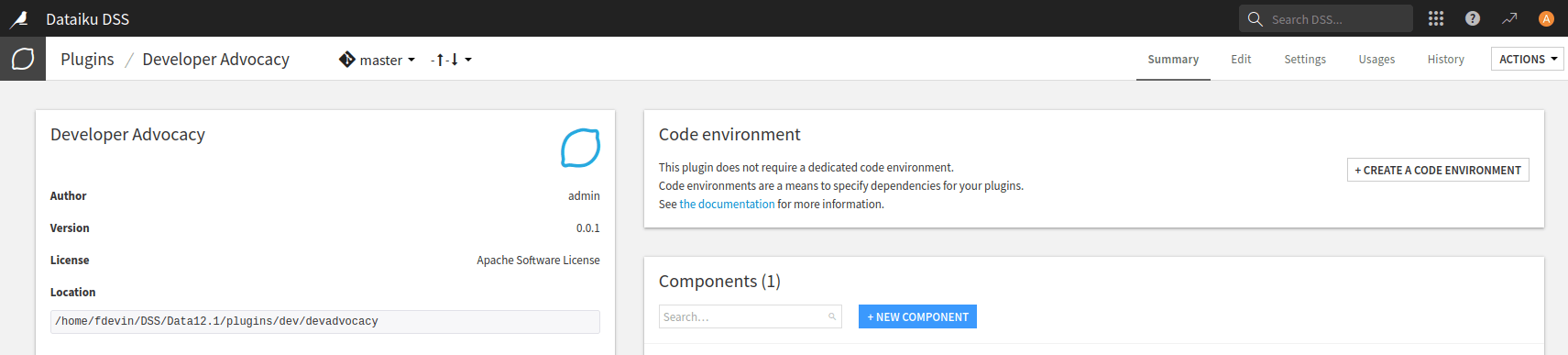
Figure 1: New component#
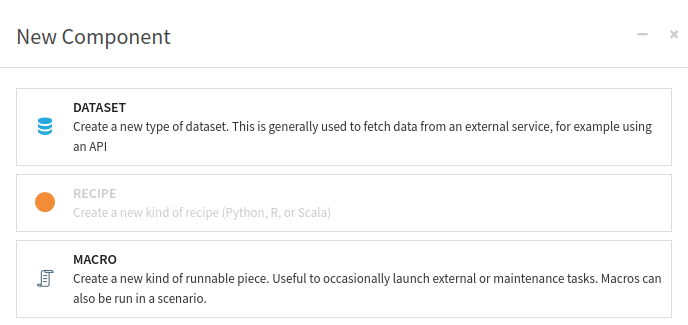
Figure 2: New macro component#
This will create a subfolder named python-connectors in your plugin directory.
Within this subfolder, a subfolder with the name of your dataset will be created.
You will find two files in this subfolder: connector.json and connector.py.
The connector.json file configures your dataset, while the connector.py file is used for processing.
Dataset default configuration#
Code 1 shows the default configuration file generated by
Dataiku.
The file includes standard objects like "meta", "params", and "permissions",
which are expected for all components.
For more information about these generic objects, please refer to Plugin Components.
/* This file is the descriptor for the Custom python dataset devadvocacy_dataset-simple-example */
{
"meta": {
// label: name of the dataset type as displayed, should be short
"label": "Custom dataset devadvocacy_dataset-simple-example",
// description: longer string to help end users understand what this dataset type is
"description": "",
// icon: must be one of the FontAwesome 3.2.1 icons, complete list here at https://fontawesome.com/v3.2.1/icons/
"icon": "icon-puzzle-piece"
},
/* Can this connector read data ? */
"readable": true,
/* Can this connector write data ? */
"writable": false,
/* params:
Dataiku will generate a formular from this list of requested parameters.
Your component code can then access the value provided by users using the "name" field of each parameter.
Available parameter types include:
STRING, INT, DOUBLE, BOOLEAN, DATE, SELECT, TEXTAREA, PRESET and others.
For the full list and for more details, see the documentation: https://doc.dataiku.com/dss/latest/plugins/reference/params.html
*/
"params": [
{
"name": "parameter1",
"label": "User-readable name",
"type": "STRING",
"description": "Some documentation for parameter1",
"mandatory": true
},
{
"name": "parameter2",
"type": "INT",
"defaultValue": 42
/* Note that standard json parsing will return it as a double in Python (instead of an int), so you need to write
int(self.config()['parameter2'])
*/
},
/* A "SELECT" parameter is a multi-choice selector. Choices are specified using the selectChoice field*/
{
"name": "parameter8",
"type": "SELECT",
"selectChoices": [
{
"value": "val_x",
"label": "display name for val_x"
},
{
"value": "val_y",
"label": "display name for val_y"
}
]
}
]
}
Dataset default code#
Code 2 shows the default code generated by Dataiku.
This code is spread into two classes: MyConnector and CustomDatasetWriter.
You only have to define the last one if you plan to save data in your custom format
(then you should also set "writable" to true in the configuration file).
# This file is the actual code for the custom Python dataset devadvocacy_dataset-simple-example
# import the base class for the custom dataset
from six.moves import xrange
from dataiku.connector import Connector
"""
A custom Python dataset is a subclass of Connector.
The parameters it expects and some flags to control its handling by Dataiku are
specified in the connector.json file.
Note: the name of the class itself is not relevant.
"""
class MyConnector(Connector):
def __init__(self, config, plugin_config):
"""
The configuration parameters set up by the user in the settings tab of the
dataset are passed as a json object 'config' to the constructor.
The static configuration parameters set up by the developer in the optional
file settings.json at the root of the plugin directory are passed as a json
object 'plugin_config' to the constructor
"""
Connector.__init__(self, config, plugin_config) # pass the parameters to the base class
# perform some more initialization
self.theparam1 = self.config.get("parameter1", "defaultValue")
def get_read_schema(self):
"""
Returns the schema that this connector generates when returning rows.
The returned schema may be None if the schema is not known in advance.
In that case, the dataset schema will be infered from the first rows.
If you do provide a schema here, all columns defined in the schema
will always be present in the output (with None value),
even if you don't provide a value in generate_rows
The schema must be a dict, with a single key: "columns", containing an array of
{'name':name, 'type' : type}.
Example:
return {"columns" : [ {"name": "col1", "type" : "string"}, {"name" :"col2", "type" : "float"}]}
Supported types are: string, int, bigint, float, double, date, boolean
"""
# In this example, we don't specify a schema here, so Dataiku will infer the schema
# from the columns actually returned by the generate_rows method
return None
def generate_rows(self, dataset_schema=None, dataset_partitioning=None,
partition_id=None, records_limit = -1):
"""
The main reading method.
Returns a generator over the rows of the dataset (or partition)
Each yielded row must be a dictionary, indexed by column name.
The dataset schema and partitioning are given for information purpose.
"""
for i in xrange(1,10):
yield { "first_col" : str(i), "my_string" : "Yes" }
def get_writer(self, dataset_schema=None, dataset_partitioning=None,
partition_id=None):
"""
Returns a writer object to write in the dataset (or in a partition).
The dataset_schema given here will match the the rows given to the writer below.
Note: the writer is responsible for clearing the partition, if relevant.
"""
raise NotImplementedError
def get_partitioning(self):
"""
Return the partitioning schema that the connector defines.
"""
raise NotImplementedError
def list_partitions(self, partitioning):
"""Return the list of partitions for the partitioning scheme
passed as parameter"""
return []
def partition_exists(self, partitioning, partition_id):
"""Return whether the partition passed as parameter exists
Implementation is only required if the corresponding flag is set to True
in the connector definition
"""
raise NotImplementedError
def get_records_count(self, partitioning=None, partition_id=None):
"""
Returns the count of records for the dataset (or a partition).
Implementation is only required if the corresponding flag is set to True
in the connector definition
"""
raise NotImplementedError
class CustomDatasetWriter(object):
def __init__(self):
pass
def write_row(self, row):
"""
Row is a tuple with N + 1 elements matching the schema passed to get_writer.
The last element is a dict of columns not found in the schema
"""
raise NotImplementedError
def close(self):
pass
The MyConnector class is designed to help you to get started quickly.
In the comments of this class, you will find the description of all functions.
Example of processing#
As a straightforward example, you will create a Dataiku’s Plugin Dataset component to generate random data. To generate random data, you need:
The size of the dataset you want to create.
The name of the columns you want to create.
For each column, the data type of this column.
Considering this, you will have a configuration equivalent to Code 3.
{
"meta": {
"label": "Generate random data",
"description": "Generate random data",
"icon": "icon-puzzle-piece"
},
"readable": true,
"writable": false,
"params": [
{
"name": "size",
"label": "Number of records",
"type": "INT",
"description": "",
"minInt": 1,
"maxInt": 10000,
"defaultValue": 10,
"mandatory": true
},
{
"name": "columns",
"label": "Column names",
"type": "STRINGS",
"description": "List of columns that will be generated",
"mandatory": true
},
{
"name": "column_types",
"label": "Column types",
"type": "STRINGS",
"description": "Type of the columns (in the same order). Only String, number, boolean are possible. Default type: string.",
"mandatory": false
}
]
}
Once you know which columns you need to create, the code for generating data is simple, with their associated types. The highlighted lines in Code 4 show how to fill in the required types if the user doesn’t provide enough information.
The generate_random_data in Code 4
should have been put into a library, but for the simplicity of this tutorial, it has been placed at the beginning of the file.
import string
from dataiku.connector import Connector
import random
def generate_random_data(param):
if param == "string":
chars = string.ascii_letters + string.digits
return ''.join(random.choice(chars) for i in range(random.randrange(1, 100)))
if param == "number":
return random.randrange(0, 100)
if param == "boolean":
return random.choice([True, False])
class MyConnector(Connector):
"""
Generate random data
"""
def __init__(self, config, plugin_config):
"""
Initializes the dataset
Args:
config:
plugin_config:
"""
Connector.__init__(self, config, plugin_config) # pass the parameters to the base class
# perform some more initialization
self.size = self.config.get("size", 100)
self.columns = self.config.get("columns", ["first_col", "my_string"])
self.types = [col.lower() for col in self.config.get("column_types", ["string", "string"])]
# If we do not have enough types for the specified columns, complete with "string"
len_col = len(self.columns)
len_types = len(self.types)
if (len_types < len_col):
self.types.extend(["string"] * (len_col - len_types))
def get_read_schema(self):
"""
Returns the schema that this dataset generates when returning rows.
"""
types = [{"name": val[0], "type": val[1]} for val in zip(self.columns, self.types)]
return {"columns": types}
def generate_rows(self, dataset_schema=None, dataset_partitioning=None,
partition_id=None, records_limit=-1):
"""
The main reading method.
Returns a generator over the rows of the dataset (or partition)
Each yielded row must be a dictionary, indexed by column name.
The dataset schema and partitioning are given for information purpose.
"""
for i in range(0, self.size):
data = {}
for j in zip(self.columns, self.types):
data[j[0]] = generate_random_data(j[1])
yield data
Wrapping up#
Congratulations on finishing this tutorial! You now know how to create a Dataiku’s Plugin Dataset component. You can generate a dataset from an external API if you want to go further.
Here are the complete versions of the code presented in this tutorial:
connector.json
{
"meta": {
"label": "Generate random data",
"description": "Generate random data",
"icon": "icon-puzzle-piece"
},
"readable": true,
"writable": false,
"params": [
{
"name": "size",
"label": "Number of records",
"type": "INT",
"description": "",
"minInt": 1,
"maxInt": 10000,
"defaultValue": 10,
"mandatory": true
},
{
"name": "columns",
"label": "Column names",
"type": "STRINGS",
"description": "List of columns that will be generated",
"mandatory": true
},
{
"name": "column_types",
"label": "Column types",
"type": "STRINGS",
"description": "Type of the columns (in the same order). Only String, number, boolean are possible. Default type: string.",
"mandatory": false
}
]
}
connector.py
import string
from dataiku.connector import Connector
import random
def generate_random_data(param):
if param == "string":
chars = string.ascii_letters + string.digits
return ''.join(random.choice(chars) for i in range(random.randrange(1, 100)))
if param == "number":
return random.randrange(0, 100)
if param == "boolean":
return random.choice([True, False])
class MyConnector(Connector):
"""
Generate random data
"""
def __init__(self, config, plugin_config):
"""
Initializes the dataset
Args:
config:
plugin_config:
"""
Connector.__init__(self, config, plugin_config) # pass the parameters to the base class
# perform some more initialization
self.size = self.config.get("size", 100)
self.columns = self.config.get("columns", ["first_col", "my_string"])
self.types = [col.lower() for col in self.config.get("column_types", ["string", "string"])]
# If we do not have enough types for the specified columns, complete with "string"
len_col = len(self.columns)
len_types = len(self.types)
if (len_types < len_col):
self.types.extend(["string"] * (len_col - len_types))
def get_read_schema(self):
"""
Returns the schema that this dataset generates when returning rows.
"""
types = [{"name": val[0], "type": val[1]} for val in zip(self.columns, self.types)]
return {"columns": types}
def generate_rows(self, dataset_schema=None, dataset_partitioning=None,
partition_id=None, records_limit=-1):
"""
The main reading method.
Returns a generator over the rows of the dataset (or partition)
Each yielded row must be a dictionary, indexed by column name.
The dataset schema and partitioning are given for information purpose.
"""
for i in range(0, self.size):
data = {}
for j in zip(self.columns, self.types):
data[j[0]] = generate_random_data(j[1])
yield data