

Distributed ML Training using Ray#
This notebook provides an example of distributed ML training on Ray. Specifically, it illustrates how to:
Deploy a Ray Cluster on a Dataiku-managed Elastic AI cluster
Train a binary classification xgboost model in a distributed fashion on the deployed Ray Cluster.
Pre-requisites#
A code environment with a Python version supported by Ray (which at the time of writing are 3.9, 3.10 and 3.11) and with the following packages:
ray[default, train, client] xgboost lightgbm pyarrow boto3 tqdm mlflow==2.17.2 scikit-learn==1.0.2 statsmodels==0.13.5
Note
The code environment only needs to be built locally, i.e., containerized execution support is not required.
Deploying a Dataiku-managed Elastic AI cluster#
Before deploying the Ray Cluster, a Dataiku administrator must deploy an Dataiku-managed Elastic AI cluster.
A few things to keep in mind about the Elastic AI Cluster:
Dataiku recommends creating a dedicated
nodegroupto host the Ray Cluster; thenodegroupcan be static or auto-scale.Ray recommends sizing each Ray Cluster pod to take up an entire Kubernetes node.
Dataiku recommends that each cluster node have at least 64 GB RAM for typical ML workloads.
Deploying a Ray Cluster#
The procedure to deploy a Ray Cluster onto a Dataiku-managed Elastic AI cluster is as follows.
Important
Note that this procedure requires Dataiku Administrator privileges.
Install this plugin.
Navigate to the “Macros” section of a Dataiku project, search for the “Ray” macros, and select the “Start Ray Cluster” macro.
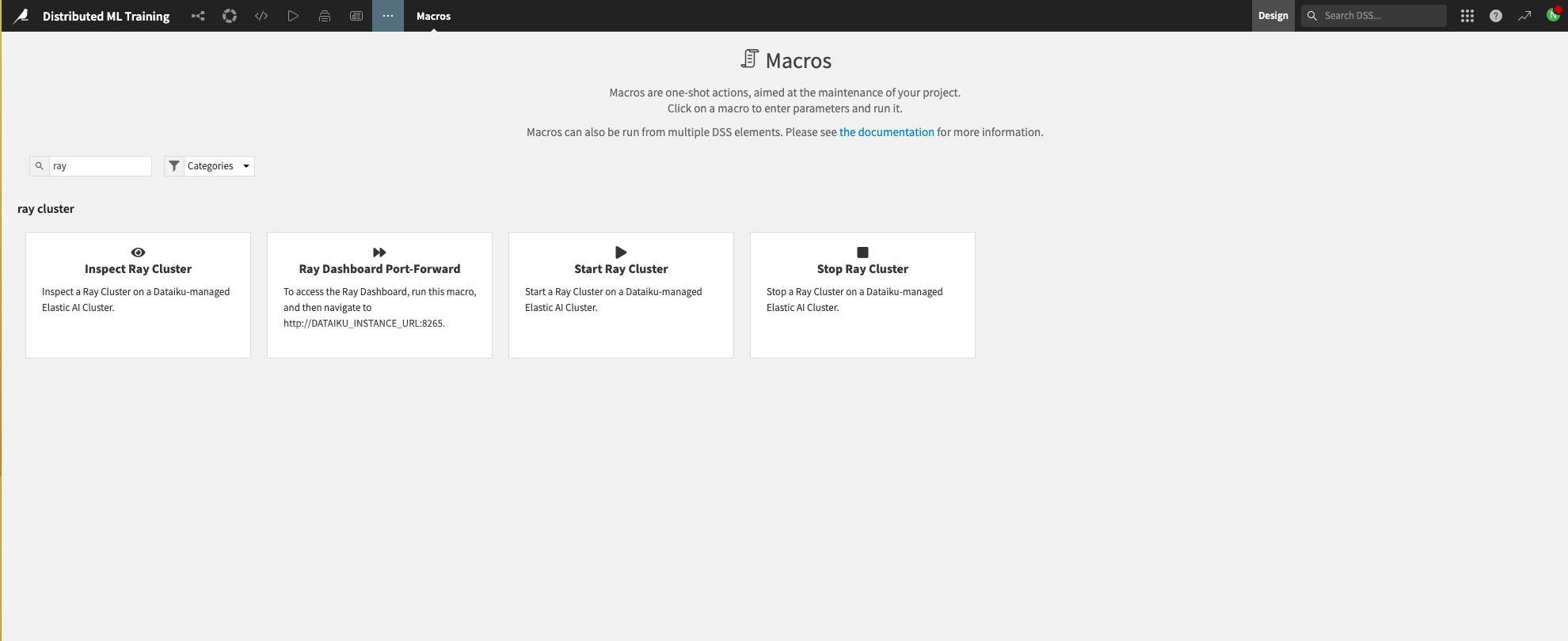
Figure 1.1 – Macros for Ray#
Fill in the macro fields, keeping in mind the following information:
KubeRay version: select the latest version from their GitHub release page.
Ray image tag: should be a valid tag from Ray’s DockerHub images; the Python version of the image tag should match the Python version of the Dataiku code environment created in the pre-requisites section.
Ray version: must match the version on the Ray image tag.
The CPU / memory request should be at least 1 CPU / 1GB RAM less than the node’s schedulable amount.
The number of Ray Cluster agents (i.e., head + worker replicas) should be equal to (or smaller) than the max size of the default Kubernetes
nodegroup.
Run the macro.
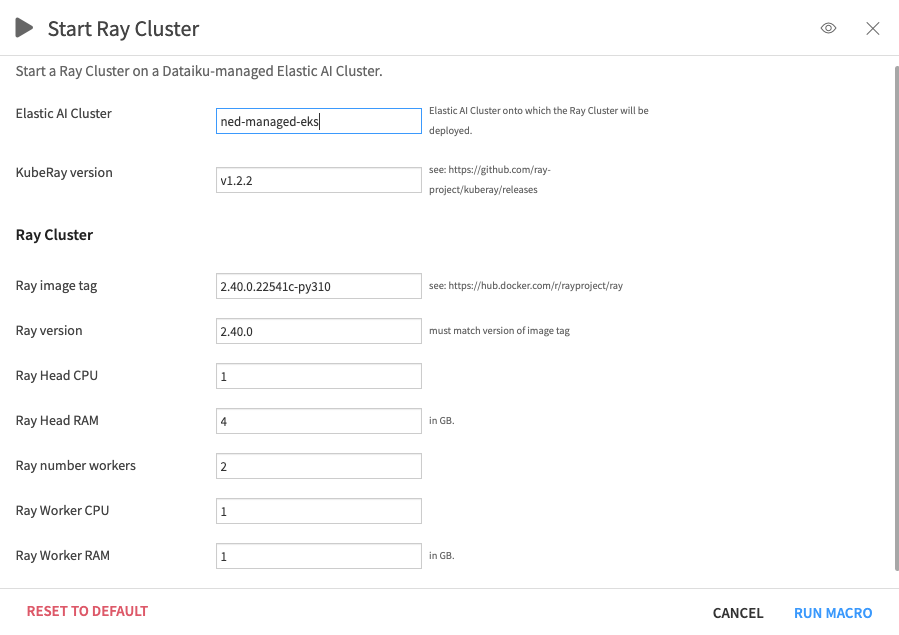
Figure 1.2 – Start macro#
Once the “Start Ray Cluster” is macro complete, run the “Inspect Ray Cluster” macro; this retrieves the Ray Cluster deployment status and provides the Ray Cluster endpoint once the cluster is ready.

Figure 1.3 – Inspect Ray Cluster#
Optionally, set up a port forwarding connection to https://github.com/dataiku/dss-plugin-rayclustere Ray Dashboard using the “Ray Dashboard Port-Forward” macro.
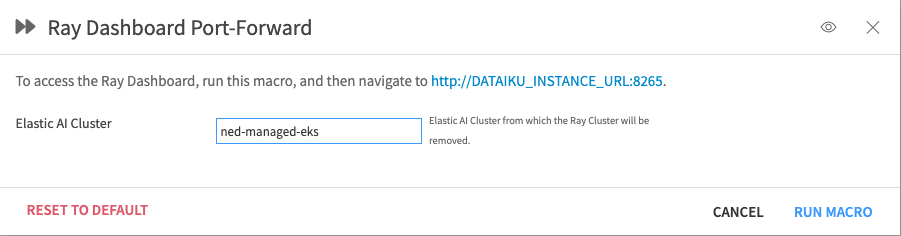
Figure 1.4 – Ray Dashboard Port-Forward#
The Ray Dashboard will then be accessible at http://\<Dataiku instance domain>:8265 while the macro is running.
Important
Note that this procedure requires SSH access to the Dataiku server.
SSH onto the Dataiku server and switch to the dssuser.
Point
kubectlto thekubeconfigof the Elastic AI cluster onto which the Ray Cluster will be deployed:export KUBECONFIG=/PATH/TO/DATADIR/clusters/<cluster name>/exec/kube_config
where
/PATH/TO/DATADIRis the path to Dataiku’s data directory, and<cluster name>is the name of the Elastic AI cluster.Install the Ray Operator on the cluster:
helm repo add kuberay https://ray-project.github.io/kuberay-helm/ helm repo update helm install kuberay-operator kuberay/kuberay-operator --version 1.2.2
Deploy the Ray Cluster:
helm install -f ray-values.yaml --version 1.2.2 raycluster kuberay/ray-cluster
where
ray-values.yamlis a file such as:image: tag: 2.40.0.22541c-py310 head: rayVersion: 2.40.0 nodeSelector: nodegroupName: rayNodegroup resources: limits: cpu: "7" memory: "30G" requests: cpu: "7" memory: "30G" worker: replicas: 2 nodeSelector: nodegroupName: rayNodegroup resources: limits: cpu: "7" memory: "30G" requests: cpu: "7" memory: "30G"
Attention
The
image.tagshould be a valid tag from one of Ray’s DockerHub images.The Python version of the
image.tagshould match the Python version of the Dataiku code environment created in the pre-requisites section.The
head.rayVersionmust match the version on theimage.tag.The
head.resources.limitsshould match thehead.resources.requestsvalues (and the same for the worker resources and limits) as per Ray’s documentation.The CPU / memory request should be at least 1 CPU / 1GB RAM less than the node’s schedulable amount.
The number of Ray Cluster agents (i.e., head + worker replicas) should be equal to (or smaller) the max size of the Kubernetes
nodegrouponto which they will be deployed (i.e., therayNodegroup).
For the complete schema of the Ray Cluster values file, see Ray’s GitHub repo.
Watch the Ray Cluster pods being created:
kubectl get pods -A -w
Once the head pod has been successfully created, describe it and determine its IP:
kubect describe pod <ray-cluster-head-pod-name>
The Ray Cluster endpoint is
http://<head pod IP>:8265.Optionally, setup a port forwarding connection to the Ray Dashboard:
kubectl port-forward service/raycluster-kuberay-head-svc --address 0.0.0.0 8265:8265
The Ray Dashboard will be accessible at
http://<Dataiku instance domain>:8265. Accessing it via a browser may require opening this port at the firewall.
If everything goes well, you should end up with something similar to:
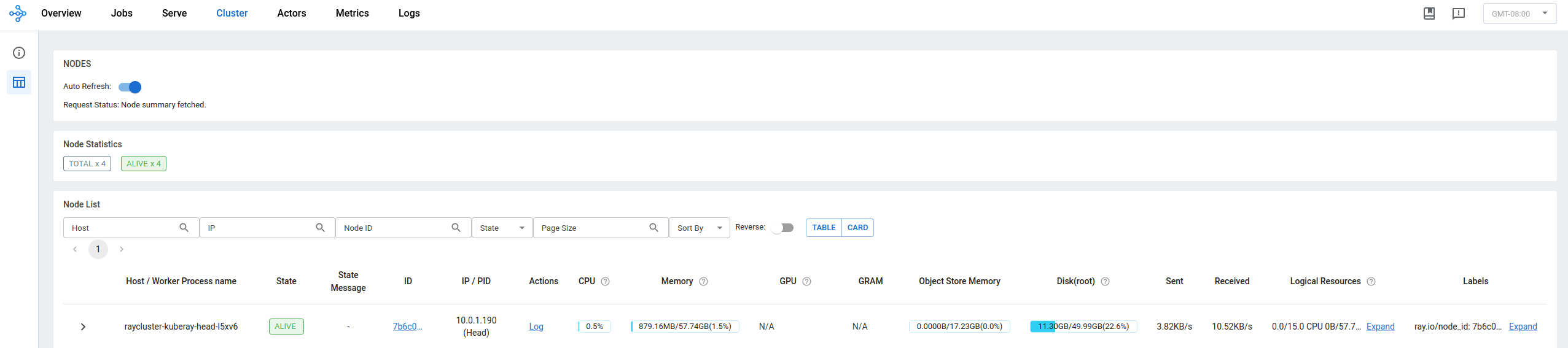
Figure 1: Ray cluster is up and running#
For more information on this procedure and how to further customize the deployment of a Ray Cluster on Kubernetes (e.g., creating an auto-scaling Ray Cluster), please refer to the relevant Ray documentation.
Train an XGBoost Model#
Now that you have a running Ray Cluster, you can train ML models on it in a distributed fashion. All they need to be provided with is the Ray Cluster endpoint, which was determined in step 6 of the Deploying a Ray Cluster section.
The following procedure illustrates how to train a binary classification xgboost model on a Ray Cluster using a data-parallel paradigm. The example draws inspiration from this code sample published in Ray’s documentation.
First, you will need to create a Project Library
called dku_ray (under the python folder) with two files, utils.py and xgboost_train.py, with the following content:
utils.py
import dataiku
from ray.job_submission import JobStatus
import time
import os
def s3_path_from_managed_folder(folder_id):
"""
Retrieves full S3 path (i.e. bucket name + path in bucjet) for managed folder.
Assumues managed folder is stored on S3 connection.
TODO: actually check this, and don't just fail.
"""
mf = dataiku.Folder(folder_id)
mf_path = mf.get_info()["accessInfo"]["bucket"] + mf.get_info()["accessInfo"]["root"]
return mf_path
def s3_credentials_from_managed_folder(folder_id):
"""
Retireves S3 credentials (access key, secret key, session token) from managed folder.
Assumues managed folder is stored on S3 connection, with AssumeRole as auth method.
TODO: actually check this, and don't just fail.
"""
client = dataiku.api_client()
project = client.get_default_project()
mf = project.get_managed_folder(folder_id) # connection only available through client
mf_connection_name = mf.get_settings().settings["params"]["connection"]
mf_connection = client.get_connection(mf_connection_name)
mf_connection_info = mf_connection.get_info()
access_key = mf_connection_info["resolvedAWSCredential"]["accessKey"]
secret_key = mf_connection_info["resolvedAWSCredential"]["secretKey"]
session_token = mf_connection_info["resolvedAWSCredential"]["sessionToken"]
return access_key, secret_key, session_token
def s3_path_from_dataset(dataset_name):
"""
Retrieves full S3 path (i.e. s3:// + bucket name + path in bucjet) for dataset.
Assumues dataset is stored on S3 connection.
TODO: actually check this, and don't just fail.
"""
ds = dataiku.Dataset(dataset_name) # resolved path and connection name via internal API
ds_path = ds.get_location_info()["info"]["path"]
return ds_path
def s3_credentials_from_dataset(dataset_name):
"""
Retireves S3 credentials (access key, secret key, session token) from S3 dataset.
Assumues dataset is stored on S3 connection, with AssumeRole as auth method.
TODO: actually check this, and don't just fail.
"""
client = dataiku.api_client()
ds = dataiku.Dataset(dataset_name) # resolved path and connection name via internal API
ds_connection_name = ds.get_config()["params"]["connection"]
ds_connection = client.get_connection(ds_connection_name)
ds_connection_info = ds_connection.get_info()
access_key = ds_connection_info["resolvedAWSCredential"]["accessKey"]
secret_key = ds_connection_info["resolvedAWSCredential"]["secretKey"]
session_token = ds_connection_info["resolvedAWSCredential"]["sessionToken"]
return access_key, secret_key, session_token
def copy_project_lib_to_tmp(file_dir, file_name, timestamp):
"""
Makes a copy of a project library file to a temporary location.
Timestamp ensures file path uniqueness.
"""
client = dataiku.api_client()
project = client.get_default_project()
project_library = project.get_library()
file_path = file_dir + file_name
file = project_library.get_file(file_path).read()
# Stage train script in /tmp
tmp_file_dir = f"/tmp/ray-{timestamp}/"
tmp_file_path = tmp_file_dir + file_name
os.makedirs(os.path.dirname(tmp_file_dir), exist_ok=True)
with open(tmp_file_path, "w") as f:
f.write(file)
return tmp_file_dir
def extract_packages_list_from_pyenv(env_name):
"""
Extracts python package list (requested + mandatory) from an environment.
Returns a list of python packages.
"""
client = dataiku.api_client()
pyenv = client.get_code_env(env_lang="PYTHON", env_name=env_name)
pyenv_settings = pyenv.get_settings()
packages = pyenv_settings.settings["specPackageList"] + pyenv_settings.settings["mandatoryPackageList"]
packages_list = packages.split("\n")
return packages_list
def wait_until_rayjob_completes(ray_client, job_id, timeout_seconds=3600):
"""
Polls Ray Job for `timeout_seconds` or until a specofoc status is reached:
- JobStatus.SUCCEEDED: return
- JobStatus.STOPPED or JobStatus.FAILED: raise exception
"""
start = time.time()
while time.time() - start <= timeout_seconds:
status = ray_client.get_job_status(job_id)
print(f"Ray Job `{job_id}` status: {status}")
if (status == JobStatus.SUCCEEDED) or (status == JobStatus.STOPPED) or (status == JobStatus.FAILED):
print("Ray training logs: \n", ray_client.get_job_logs(job_id))
break
time.sleep(1)
if (status == JobStatus.SUCCEEDED):
print("Ray Job {job_id} completed successfully.")
return
else:
raise Exception("Ray Job {job_id} failed, see logs above.")
xgboost_train.py
# Inspired by from:
# https://github.com/ray-project/ray/blob/master/release/train_tests/xgboost_lightgbm/train_batch_inference_benchmark.py
import json
import numpy as np
import os
import pandas as pd
import time
from typing import Dict
import xgboost as xgb
from pyarrow import fs
import ray
from ray import data
from ray.train.xgboost.v2 import XGBoostTrainer # https://github.com/ray-project/ray/blob/master/python/ray/train/xgboost/v2.py#L13
from ray.train.xgboost import RayTrainReportCallback as XGBoostReportCallback
from ray.train import RunConfig, ScalingConfig
def xgboost_train_loop_function(config: Dict):
# 1. Get the dataset shard for the worker and convert to a `xgboost.DMatrix`
train_ds_iter = ray.train.get_dataset_shard("train")
train_df = train_ds_iter.materialize().to_pandas()
label_column, params = config["label_column"], config["params"]
train_X, train_y = train_df.drop(label_column, axis=1), train_df[label_column]
dtrain = xgb.DMatrix(train_X, label=train_y)
# 2. Do distributed data-parallel training.
# Ray Train sets up the necessary coordinator processes and
# environment variables for your workers to communicate with each other.
report_callback = config["report_callback_cls"]
xgb.train(
params,
dtrain=dtrain,
num_boost_round=10,
callbacks=[report_callback()],
)
def train_xgboost(data_path: str,
data_filesystem,
data_label: str,
storage_path: str,
storage_filesystem,
num_workers: int,
cpus_per_worker: int,
run_name: str) -> ray.train.Result:
print(storage_path)
ds = data.read_parquet(data_path, filesystem=data_filesystem)
train_loop_config= {
"params": {
"objective": "binary:logistic",
"eval_metric": ["logloss", "error"]
},
"label_column": data_label,
"report_callback_cls": XGBoostReportCallback
}
trainer = XGBoostTrainer(
train_loop_per_worker=xgboost_train_loop_function,
train_loop_config=train_loop_config,
scaling_config=ScalingConfig( # https://docs.ray.io/en/latest/train/api/doc/ray.train.ScalingConfig.html
num_workers=num_workers,
resources_per_worker={"CPU": cpus_per_worker},
),
datasets={"train": ds},
run_config=RunConfig( # https://docs.ray.io/en/latest/train/api/doc/ray.train.RunConfig.html
storage_path=storage_path,
storage_filesystem=storage_filesystem,
name=run_name
),
)
result = trainer.fit()
return result
def main(args):
# Build pyarrow filesystems with s3 credentials
# https://arrow.apache.org/docs/python/generated/pyarrow.fs.S3FileSystem.html#pyarrow.fs.S3FileSystem
s3_ds = fs.S3FileSystem(
access_key=args.data_s3_access_key,
secret_key=args.data_s3_secret_key,
session_token=args.data_s3_session_token
)
s3_mf = fs.S3FileSystem(
access_key=args.storage_s3_access_key,
secret_key=args.storage_s3_secret_key,
session_token=args.storage_s3_session_token
)
print(f"Running xgboost training benchmark...")
training_start = time.perf_counter()
result = train_xgboost(
args.data_s3_path,
s3_ds,
args.data_label_column,
args.storage_s3_path,
s3_mf,
args.num_workers,
args.cpus_per_worker,
args.run_name
)
training_time = time.perf_counter() - training_start
print("Training result:\n", result)
print("Training time:", training_time)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
# Train dataset arguments
parser.add_argument("--data-s3-path", type=str)
parser.add_argument("--data-s3-access-key", type=str)
parser.add_argument("--data-s3-secret-key", type=str)
parser.add_argument("--data-s3-session-token", type=str)
parser.add_argument("--data-label-column", type=str)
# storage folder arguments
parser.add_argument("--storage-s3-path", type=str)
parser.add_argument("--storage-s3-access-key", type=str)
parser.add_argument("--storage-s3-secret-key", type=str)
parser.add_argument("--storage-s3-session-token", type=str)
# compute arguments
parser.add_argument("--num-workers", type=int, default=2)
parser.add_argument("--cpus-per-worker", type=int, default=1)
parser.add_argument("--run-name", type=str, default="xgboost-train")
args = parser.parse_args()
main(args)
Second, you must create a dataset in the Flow to be used as the model’s training dataset.
This example (and the code of the dku_ray project library) assumes that this dataset is:
on S3
in the parquet format
on a Dataiku S3 connection that uses STS with AssumeRole as its authentication method and that the user running the code has “details readable by” access on the connection
Note
Modifying the code with different connection and/or authentication types should be straightforward.
Third, you must create a managed folder in the Flow, where Ray will store the training process outputs. Similar to the training dataset, this example assumes the managed folder is on an S3 connection with the same properties listed above.
Finally, the following code can be used to train a model on the input dataset. In this case, the “avocado_transactions_train” is a slightly processed version of this Kaggle dataset.
Importing the required packages#
import dataiku
from dku_ray.utils import (
s3_path_from_managed_folder,
s3_credentials_from_managed_folder,
s3_path_from_dataset,
s3_credentials_from_dataset,
copy_project_lib_to_tmp,
extract_packages_list_from_pyenv,
wait_until_rayjob_completes
)
import time
import os
from ray.job_submission import JobSubmissionClient
Setting the default parameters#
# Dataiku client
client = dataiku.api_client()
project = client.get_default_project()
# Script params: YOU NEED TO ADAPT THIS PART
train_dataset_name = "avocado_transactions_train"
target_column_name = "type" # includes the
managed_folder_id = "CcLoevDh"
ray_cluster_endpoint = "http://10.0.1.190:8265"
train_script_filename = "xgboost_train.py" # name of file in Project Library
train_script_dir = "/python/dku_ray/" # in project libs
ray_env_name = "py310_ray" # dataiku code environment name
num_ray_workers = 3 # num workers and cpus per worker should be sized approriately,
# based on the size of the Ray Cluster deployed
cpus_per_ray_worker = 10
timestamp = int(time.time()*100000) # unix timestamp in seconds
Setting the training script#
# Train script
## Copy train script to temporary location (as impersonated users can't traverse project libs)
tmp_train_script_dir = copy_project_lib_to_tmp(train_script_dir, train_script_filename, timestamp)
# Inputs & outputs
## (a) Retrieve S3 input dataset path and credentials
## Note: connection should be S3 and use AssumeRole; dataset file format should be parquet
ds_path = s3_path_from_dataset(train_dataset_name)
ds_access_key, ds_secret_key, ds_session_token = s3_credentials_from_dataset(train_dataset_name)
## (b) Retrieve output S3 managed folder path and credentials
## Note: connection should be S3 and use AssumeRole
storage_path = s3_path_from_managed_folder(managed_folder_id)
storage_access_key, storage_secret_key, storage_session_token = s3_credentials_from_managed_folder(managed_folder_id)
Submitting the job to Ray#
# Submit to remote cluster
# Useful links:
# Ray Jobs SDK: https://docs.ray.io/en/latest/cluster/running-applications/job-submission/sdk.html
# Runtime env spec: https://docs.ray.io/en/latest/ray-core/api/runtime-env.html
ray_client = JobSubmissionClient(ray_cluster_endpoint)
entrypoint = f"python {train_script_filename} --run-name=\"xgboost-train-{timestamp}\" " + \
f"--data-s3-path=\"{ds_path}\" --data-label-column=\"{target_column_name}\" " + \
f"--data-s3-access-key={ds_access_key} --data-s3-secret-key={ds_secret_key} --data-s3-session-token={ds_session_token} " + \
f"--storage-s3-path=\"{storage_path}\" " + \
f"--storage-s3-access-key={storage_access_key} --storage-s3-secret-key={storage_secret_key} --storage-s3-session-token={storage_session_token} " + \
f"--num-workers={num_ray_workers} --cpus-per-worker={cpus_per_ray_worker}"
# Extract python package list from env
python_packages_list = extract_packages_list_from_pyenv(ray_env_name)
job_id = ray_client.submit_job(
entrypoint=entrypoint,
runtime_env={
"working_dir": tmp_train_script_dir,
"pip": python_packages_list
}
)
# Wait until job fails or succeeds
wait_until_rayjob_completes(ray_client, job_id)
Once you’ve submitted the job, you can see it running in the Ray dashboard shown below:
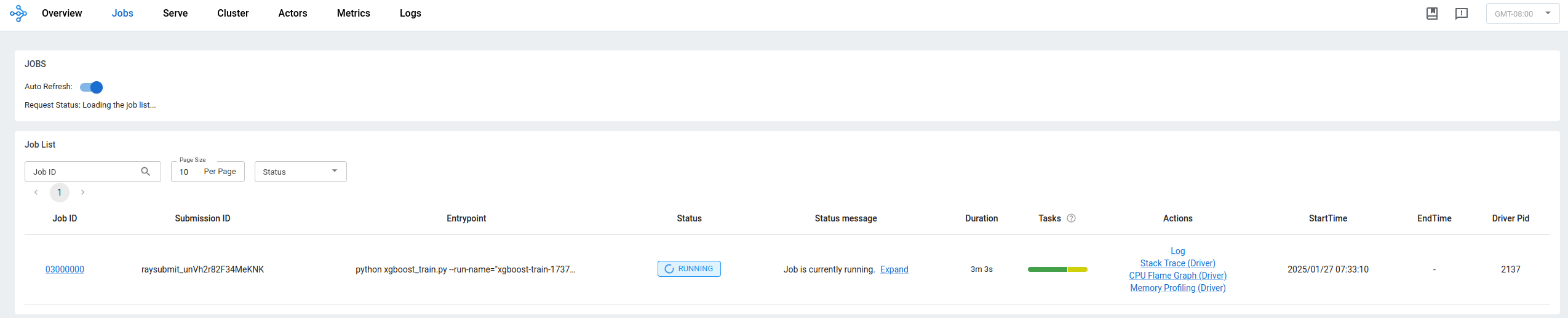
Figure 2 – Ray dashboard showing the running job#
Once the job succeeds, you should be able to find the xgboost object in the managed folder designated as the “output.”
Conclusion#
You now know how to set up a Ray cluster to achieve distributed learning using the xgboost algorithm.
Adapting this tutorial to your preferred algorithm and/or cluster should be easy.
Here is the complete code for this tutorial:
code.py
import dataiku
from dku_ray.utils import (
s3_path_from_managed_folder,
s3_credentials_from_managed_folder,
s3_path_from_dataset,
s3_credentials_from_dataset,
copy_project_lib_to_tmp,
extract_packages_list_from_pyenv,
wait_until_rayjob_completes
)
import time
import os
from ray.job_submission import JobSubmissionClient
# Dataiku client
client = dataiku.api_client()
project = client.get_default_project()
# Script params: YOU NEED TO ADAPT THIS PART
train_dataset_name = "avocado_transactions_train"
target_column_name = "type" # includes the
managed_folder_id = "CcLoevDh"
ray_cluster_endpoint = "http://10.0.1.190:8265"
train_script_filename = "xgboost_train.py" # name of file in Project Library
train_script_dir = "/python/dku_ray/" # in project libs
ray_env_name = "py310_ray" # dataiku code environment name
num_ray_workers = 3 # num workers and cpus per worker should be sized approriately,
# based on the size of the Ray Cluster deployed
cpus_per_ray_worker = 10
timestamp = int(time.time()*100000) # unix timestamp in seconds
# Train script
## Copy train script to temporary location (as impersonated users can't traverse project libs)
tmp_train_script_dir = copy_project_lib_to_tmp(train_script_dir, train_script_filename, timestamp)
# Inputs & outputs
## (a) Retrieve S3 input dataset path and credentials
## Note: connection should be S3 and use AssumeRole; dataset file format should be parquet
ds_path = s3_path_from_dataset(train_dataset_name)
ds_access_key, ds_secret_key, ds_session_token = s3_credentials_from_dataset(train_dataset_name)
## (b) Retrieve output S3 managed folder path and credentials
## Note: connection should be S3 and use AssumeRole
storage_path = s3_path_from_managed_folder(managed_folder_id)
storage_access_key, storage_secret_key, storage_session_token = s3_credentials_from_managed_folder(managed_folder_id)
# Submit to remote cluster
# Useful links:
# Ray Jobs SDK: https://docs.ray.io/en/latest/cluster/running-applications/job-submission/sdk.html
# Runtime env spec: https://docs.ray.io/en/latest/ray-core/api/runtime-env.html
ray_client = JobSubmissionClient(ray_cluster_endpoint)
entrypoint = f"python {train_script_filename} --run-name=\"xgboost-train-{timestamp}\" " + \
f"--data-s3-path=\"{ds_path}\" --data-label-column=\"{target_column_name}\" " + \
f"--data-s3-access-key={ds_access_key} --data-s3-secret-key={ds_secret_key} --data-s3-session-token={ds_session_token} " + \
f"--storage-s3-path=\"{storage_path}\" " + \
f"--storage-s3-access-key={storage_access_key} --storage-s3-secret-key={storage_secret_key} --storage-s3-session-token={storage_session_token} " + \
f"--num-workers={num_ray_workers} --cpus-per-worker={cpus_per_ray_worker}"
# Extract python package list from env
python_packages_list = extract_packages_list_from_pyenv(ray_env_name)
job_id = ray_client.submit_job(
entrypoint=entrypoint,
runtime_env={
"working_dir": tmp_train_script_dir,
"pip": python_packages_list
}
)
# Wait until job fails or succeeds
wait_until_rayjob_completes(ray_client, job_id)